









 About... About...
©1999-2002
Osmar R. Zaïane
(zaiane@cs.ualberta.ca)
|
|
 Activities
Activities
| Class presentations |
|
Each student is expected to read and present one paper from the research literature that I provided. You should view this as if
you were presenting the paper at a conference. Be prepared to answer detailed technical questions about the content of the paper or related to the topic of the paper. However, you do not need to be an advocate
for the paper. You do not have to defend it. If you want to
critique it and highlight the problems and weaknesess: go ahead.
In your presentation, you should properly place the work within the field, cite
if possible related work, and clearly indicate the innovative aspects of the work
and its contribution to the field, as well as explain the details of the
ideas, algorithms and experiments presented in the paper.
Students must prepare their own materials for presentation. I highly
recommend powerpoint slides. However, transparencies are fine
too. Bring me or send me by e-mail the final slides one hour before
class. I will make sure the files are transfered to the classroom
computer before the class starts.
These slides are also made available to the other students via our
course web
site.
Paper presenters who have difficulty understanding the paper are
encouraged to discuss it with the students reviewing the paper. This
could provide them with a better intuition about the content of the
paper and thus help them prepare their presentation.
If the student is not present (does not show up) for his/her presentation, the evaluation is automatically 0 (zero) unless a good medical justification is given. For any serious absence, I should be advised early enough to organize a reshuffling of the presentations.
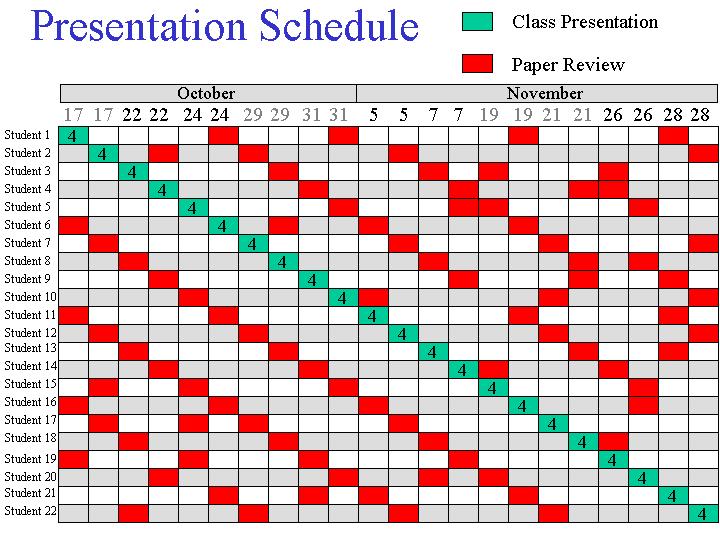
Important Dates
The class presentation will count 20% of the overall grade.
|
| Assignments |
|
Each student is expected to review four papers, and write a written report for each of the four assigned papers. The review should be about 2 pages and should be written as if you were reviewing a journal article or a paper submitted to a conference program committee.
The review should contain at least these sections:
1-Brief summary of the main contributions of the paper
2-Elaboration on the positive aspects presented in the paper
3-Elaboration on the negative aspects presented in the paper
4-Comments on how to improve the ideas/issues/experiments presented in the paper.
Here is an article giving suggestions on how to review a paper (Alan Jay Smith, The Task of the Referee, IEEE, 1990)
Reviews should be an independent analysis of the paper.
Collaboration to understand the intricacies of the paper is acceptable, but collaboration in reviewing the paper is not an advisable practice. Students should write their own reviews and interpretation. This way different opinions may emerge during classroom
discussions and the discussions end up more interesting and instructive.
Reviews should be snet by e-mail (in pdf format) and handed in during
class time in hardcopy or before. Defaulted reviews count for 0 (zero).
Important Dates
See table of the paper presentations above.
Assignments will count together 16% of the overall grade.
|
| Date | Paper | Presenter | Reviewers |
|---|
| Oct 17 |
CLOSET:
An Efficient Algorithm for Mining Frequent Closed Itemsets 
J. Pei, J. Han, and R. Mao,
ACM-SIGMOD Int. Workshop on Data Mining and Knowledge Discovery (DMKD'00)}, Dallas, TX, May 2000.
Related Papers
CHARM: An Efficient Algorithm for Closed Itemset Mining  , M. Zaki, and C-J Hsiao, SIAM SDM 2002, Arlington, VA, April 2002. , M. Zaki, and C-J Hsiao, SIAM SDM 2002, Arlington, VA, April 2002.
|
An, Zhibin (slides  ) ) |
- Guo, Yuhong
- Nulahmet, Mnawer
- Wang, Yang
- Peter Kai Yue
|
|---|
H-Mine: Hyper-Structure Mining of Frequent Patterns in Large
Databases
J. Pei, J. Han, H. Lu, S. Nishio, S. Tang, and D. Yang,
Int. Conf. on Data Mining (ICDM'01), San Jose, CA, Nov. 2001.
Related Papers
Mining Frequent Patterns without Candidate Generation , J. Han, J. Pei,
and Y. Yin, ACM-SIGMOD 2000, Dallas, TX, May 2000.
|
Mocofan, Marian Leonid (slides ) |
- Hou, Guiwen
- Pei, Yaling
- Tu, Xin
- Wu, Yaohua
|
| Oct 22 |
Selecting the right interestingness measure for association patterns 
Pang-Ning Tan, Vipin Kumar, Jaideep Srivastava
ACM SIGKDD 2002, pp 32-41 |
Cai, Zhipeng (slides ) |
- Li, Wenxin
- Shi, Zhigang
- Xing, Zhenchang
- Zou, Shoudong
|
|---|
Optimization of Constrained Frequent Set Queries with 2-Variable Constraints
L. V. S. Lakshmanan, R. Ng, J. Han and A. Pang, . In Proc. of the ACM SIGMOD 1999.
Related paper
Exploratory mining and pruning optimizations of constrained associations rules R. Ng, L. V. S. Lakshmanan, J. Han, and A. Pang. In Proc. 1998 ACM SIGMOD 1998.
|
Chen, Joyce Hui (slides ) |
- Atherton, Michael James
- Malenfant, Rene Michael
- Sun, Lisheng
- Zhang, Jingyue
|
| Oct 24 |
A Simulation Study of Three Related Causal Data Mining Algorithms
S. Mani and G. F. Cooper, International Workshop on
Artificial Intelligence and Statistics, 2001, p73--80. San Francisco, CA.
Related paper
S. Brin, R. Motwani and C. Silverstein. Beyond Market Baskets: Generalizing Association Rules to Correlations . In Proc. of the ACM SIGMOD Conference on Management of
Data, 1997.
C. Silverstein, S. Brin, R. Motwani, and J. Ullman. Scalable techniques for mining causal structures . In Proc. 1998 Int. Conf. Very Large Data Bases, 1998.
|
Ding, Meng (slides ) |
- Mocofan, Marian Leonid
- Tu, Xin
- Wu, Yaohua
- Yap, Peter Kai Yue
|
|---|
Efficient Mining of Association Rules in Distributed Databases
D. Cheung, V. Ng, A. Fu, Y. Fu, IEEE Transactions on Knowledge and
Data Engineering ( TKDE), Vol. 8, No. 6, pages 911-922. Dec, 1996.
|
Guo, Yuhong (slides ) |
- An, Zhibin
- Nulahmet, Mnawer
- Wang, Yang
- Zhang, Qiongyun
|
| Oct 29 |
Privacy-Preserving Data
Mining
R. Agrawal and R. Srikant, ACM SIGMOD 2000, Dallas, May 2000.
|
Hou, Guiwen (slides ) |
- Atherton, Michael James
- Pei, Yaling
- Wu, Yaohua
- Zou, Shoudong
|
|---|
Privacy Preserving Data Mining
Y. Lindell and B. Pinkas, In Crypto 2000, Springer-Verlag (LNCS
1880), pages 36-54, 2000. |
Li, Wenxin (slides ) |
- Cai, Zhipeng
- Guo, Yuhong
- Shi, Zhigang
- Xing, Zhenchang
|
| Oct 31 |
A Robust Outlier Detection Scheme in Large Data Sets
J. Tang, Z. Chen, A. Fu , D. Cheung, the Sixth Pacific-Asia Conference on
Knowledge Discovery and Data Mining, (PAKDD), Taipei, 6-8 May, 2002.
|
Malenfant, Rene Michael (slides ) |
- Chen, Joyce Hui
- Sun, Lisheng
- Yap, Peter Kai Yue
- Zhang, Qiongyun
|
|---|
Mining Top-n Local Outliers in Large Databases
W. Jin, K.H. Tung and J. Han, ACM
SIGKDD 2001, San Jose, California, Aug. 2001. |
Atherton, Michael James |
- An, Zhibin
- Ding, Meng
- Tu, Xin
- Zhang, Jingyue
|
| Nov 5 |
Visualizing Association Mining Results through Hierarchical Clusters
Noel, S., Raghavan, V., and
C.-H. H. Chu, ICDM'2001, pp 425-432 (also in HTML  ) ) |
Nulahmet, Mnawer (slides ) |
- Guo, Yuhong
- Mocofan, Marian Leonid
- Wang, Yang
- Zhang, Qiongyun
|
|---|
Finding Generalized Projected Clusters in High Dimensional Spaces
Charu C. Aggarwal, Philip S. Yu,
ACM SIGMOD 2000 |
Pei, Yaling (slides ) |
- Atherton, Michael James
- Hou, Guiwen
- Wu, Yaohua
- Zou, Shoudong
|
| Nov 7 |
Incremental Document Clustering for Web Page Classification
Wai-Chiu Wong, A. Fu, Chapter in the book titled ``Enabling Society
with Information Technology'', Springer-Verlag, pages 101-110, 2002.
Related paper
Incremental Document Clustering for Web Page Classification
Wai Chiu Wong and A. Fu, IEEE 2000 Int. Conf. on Info. Society in the
21st century: emerging technologies and new challenges (IS2000), Nov 5-8, 2000, Japan (Best Paper Award).
|
Shi, Zhigang (slides ) |
- Cai, Zhipeng
- Li, Wenxin
- Xing, Zhenchang
- Zhang, Jingyue
|
|---|
Understanding web usage at different levels of
abstraction: coarsening and visualising sequences
Bettina Berendt, ACM SIGKDD WEBKDD
Workshop "Mining Log Data Across All
Customer TouchPoints", San
Francisco, CA, August 26, 2001
|
Sun, Lisheng (slides ) |
- Chen, Joyce Hui
- Ding, Meng
- Malenfant, Rene Michael
- Yap, Peter Kai Yue
|
| Nov 19 |
Efficient Mining of Partial Periodic Patterns in Time Series Database
J. Han, G. Dong, and Y. Yin, Int. Conf. on Data Engineering (ICDE'99), Sydney,
Australia, March 1999, pp. 106-115. |
Tu, Xin (slides ) |
- Cai, Zhipeng
- Ding, Meng
- Sun, Lisheng
- Zhang, Jingyue
|
|---|
On the need for time series data mining benchmarks: A survey and empirical demonstration
Eamonn Keogh, Shruti Kasetty,
ACM SIGKDD 2002, pp 102-111
|
Wang, Yang (slides ) |
- An, Zhibin
- Guo, Yuhong
- Nulahmet, Mnawer
- Zhang, Qiongyun
|
| Nov 21 |
Finding Surprising Patterns in a Time Series Database In Linear Time and Space
Keogh, E., Lonardi, S and Chiu,
W., ACM SIGKDD 2002, pp 550-556. (extended version) |
Wu, Yaohua (slides ) |
- Hou, Guiwen
- Mocofan, Marian Leonid
- Pei, Yaling
- Zou, Shoudong
|
|---|
Personalization from Incomplete Data: What You Don't Know Can Hurt
Balaji Padmanabhan, Zhiqiang
Zheng, Steven O. Kimbrough, ACM SIGKDD 2001 |
Xing, Zhenchang (slides ) |
- Chen, Joyce Hui
- Li, Wenxin
- Malenfant, Rene Michael
- Shi, Zhigang
|
| Nov 26 |
Evaluating Boosting Algorithms to Classify Rare Classes: Comparison and Improvements
Mahesh Joshi, Vipin Kumar and Ramesh Agarwal
IEEE International Conference on Data Mining (ICDM'01), San Jose, CA, November 2001
Related Papers
Predicting Rare Classes: Can Boosting Make Any Weak Learner Strong? Mahesh Joshi, Ramesh Agarwal, Vipin Kumar,
ACM SIGKDD 2002, Edmonton, Canada, July 2002
On Evaluating Performance of Classifiers for Rare Classes Mahesh Joshi, Submitted to the IEEE International Conference on Data Mining (ICDM'02), Japan, December 2002.
|
Yap, Peter Kai Yue (slides ) |
- Cai, Zhipeng
- Chen, Joyce Hui
- Sun, Lisheng
- Xing, Zhenchang
|
|---|
Learning and Making Decisions When Costs and Probabilities are Both Unknown
B. Zadrozny and C. Elkan., ACM
SIGKDD 2001 |
Zhang, Jingyue (slides ) |
- Ding, Meng
- Li, Wenxin
- Tu, Xin
- Wang, Yang
|
| Nov 28 |
Efficient Data Mining for Path Traversal Patterns
Ming-Syan Chen, Jong Soo Park, and Philip S. Yu IEEE Transactions on Knowledge and Data Engineering, Vol. 10, No. 2, March/April 1998
|
Zhang, Qiongyun |
- An, Zhibin
- Malenfant, Rene Michael
- Nulahmet, Mnawer
- Shi, Zhigang
|
|---|
Using Artificial Anomalies to Detect Unknown and Known Network Intrusions
W. Fan, M. Miller, S. Stolfo, W. Lee, P. Chan, IEEE Intl. Conf. Data Mining, 2001.
Related Papers
Learning
Nonstationary Models of Normal Network Traffic for Detecting Novel
Attacks , M. Mahoney and P. Chan, ACM SIGKDD 2002, pp. 376-385, 2002.
Real Time Data
Mining-based Intrusion Detection , W. Lee, S. Stolfo, P. Chan, E. Eskin, W. Fan, M. Miller, S. Hershkop, and J. Zhang, Proc. Second DARPA Information
Survivability Conference and Exposition, pp. I85-100, 2001.
|
Zou, Shoudong |
- Atherton, Michael James
- Hou, Guiwen
- Mocofan, Marian Leonid
- Pei, Yaling
|
| Projects |
Suggested Projects: (strong suggestion)
Association Rules
Project 1: Frequent-pattern growth on disk
The Frequent-pattern growth algorithm mines frequent patterns from a tree structure called FP-Tree. This FP-tree is typically located in main memory and the approach assumes an almost infinite memory space. Assuming a very limited memory space, implement an efficient representation of the FP-tree on disk such that an similar approach as FP-growth can be used directly from disk.
Students: Leonid Mocofan
Reference Student: William Cheung
Project 2: Constaint-Based Mining
Constraint-based Association Rule Mining for queries such as "find all frequent itemsets where the total price is no more than $100" has received much attention, for it can improve the mining efficiency. Some important classes of rule constraints such as antimonotone, monotone, succinct constraint are discussed in Ch6.6.2.
In this project, you are required to implement these constraints based on the Apriori algorithm, and compare your constraint-based algorithm with the original Apriori algorithm. When implementing the rule constraints, the naive approach is to deal with them one by one, and only one type of constraint is handled at a time. Can you handle more then one type at the same time to further improve the efficiency? For example, can you simultaneously take advantage of both monotone and antimonotone to mine constraint-based itemsets?
Students: Shoudong Zou and Guiwen Hou
Reference Student: Jia Li
Project 3: Sequential Patterns vs. Association Rules
Sequential Patterns and Association Rules are two similar data mining techniques. They are only different in that the patterns in the former are time-ordered. It seems that Sequential Patterns plays a more important role in Web Usage Mining since it considers the time order between items. However, some people argue that when the application is to provide dynamic recommendations for web users, Association Rules performs better. In this project, you are required to build a prototype of a recommender agent using both of the techniques and compare their performance in your system.
Number of students: 2
Reference Student: Jia Li
Classification
Project 4: User interface for text categorization
Knowledge Discovery is an iterative process and even data mining one single step of this process is also iterative, interactive sub-process needing a lot of tuning, trials, adjustments, interpretations, etc.
This also true for the case of text categorization. There is a step in which a user selects a document set, designates a split (training/testing) and starts training. The model is tested and evaluated in a second step, possibly using different accuracy measures. In a final step the model is used to categorize new documents. One can also consider yet another step where the result of the classification (or the model) is visualized.
Design a user interface that incorporates all these steps for a text document categorizer using an associative classifier. Assume you have a module that gets as input transactions and some thresholds and returns a set of association rules, as well as a module that classifies new transactions.
The user interface should allow to control the parameters, the control of different accuracy measures, as well as visualize the association rules (model) and the classification results.
Number of students: 2
Reference Student: Luiza Antonie
Project 5: Associative classifier with negative association rules
Recently a new classification method was proposed in the Data
Mining community: associative classification.
In this case the learning model consists of association rules mined. The main idea behind this approach is to discover strong patterns that are associated with the class labels. Three such models were presented in the literature: CMAR, CBA and ARC-AC/ARC-BC. All of these algorithms deal with occurrence of items in transactions and do not consider the absence of items. Devise an associative classifier that takes into account negative associations. Test your approach on UCI archive datasets.
Students: Xin Tu and René Malenfant
Reference Student: Luiza Antonie
Project 6: Associative classifier with reoccurring items
Recently a new classification method was proposed in the Data
Mining community: associative classification.
In this case the learning model consists of association rules mined. The main idea behind this approach is to discover strong patterns that are associated with the class labels. Three such models were presented in the literature: CMAR, CBA and ARC-AC/ARC-BC. All of these algorithms deal with binary association rules and assumes attribute values to appear at most ones in each transaction and use simple apriori-like or FP-growth to associations. Consider that attribute values can reoccur in the same transactions, devise an associative classifier that takes into account reoccurring items.
Number of students: 2
Reference Student: Luiza Antonie
Project 7: Classifier evaluation
Recently a new classification method was proposed in the Data
Mining community: associative classification.
In this case the learning model consists of association rules mined. The main idea behind this approach is to discover strong patterns that are associated with the class labels. Three such models were presented in the literature: CMAR, CBA and ARC-AC/ARC-BC. Implement CBA, CMAR and compare them on UCI datasets using a variety of measures. See �Selecting the right interestingness measure for association patterns, by Tan, Kumar and Srivastava and published at KDD 2002, for the appropriate measures to test. Use UCI archives for datasets.
Students: Yaohua Wu and Qiongyun Zhang
Reference Student: Luiza Antonie
Clustering
Project 8: Clustering With Constraints
Given a hull H defined by a set of points S within a data-space T in D dimensions, define the relationship between any two points a and b given that H is a connector (a bridge) or an obstacle. The hull can be modelled using 1. triangulation and 2. interpolation. The method(s) should be as fast and efficient as possible and establish whether b is visible to a directly, whether they can be connected and the shortest path between them. Given this result, any clustering algorithm can be used to cluster the data in the presence of physical constraints, namely obstacles or bridges.
Initially it can be assumed that the dimensions are all ordinal. Then a mixed ordinal and categorical space can be considered.
A sub project is establishing distance in categorical spaces where no defined relationship exists between the values of the attributes.
Students: Peter Yap
Reference Student: Andrew Foss
Project 9: Synthetic Data Generation
The task is to generate datasets in D dimensions with a given number of clusters k and N data points. The density of noise should be specifiable along with a difficulty level or perhaps several. Difficulties include spacing between clusters, cluster shape and arrangement. Spherical clusters are �easy� while long thin or arbitrarily shaped ones are more difficult. Clusters within clusters are even more difficult. Clusters embedded within clusters are most difficult. Another cause of difficulty is different cluster densities as in the case of clusters embedded within clusters.
Initially it can be assumed that the dimensions are all ordinal. Then a mixed ordinal and categorical space can be considered.
Students: Yaling Pei and Zhigang Shi
Reference Student: Andrew Foss
Project 10: Clustering text documents
The task is to group text documents in clusters such that documents in the same cluster in the same cluster are similar to each other with regard to content. The content consists essentially of words. These words can be considered in terms of frequencies or LSA weights. Consider the case where the number of desired clusters is known and the case where the number of clusters is unknown.
Students: Yang Wang and Zhibin An
Project 11: Clustering web pages based on access
Clustering is wide-used in Web Usage Mining. Typically, web sessions are clustered in which each cluster represents a group of transactions that are similar based on co-occurrence patterns of URL references. Another approach we can consider is to cluster URL references based on how often they occur together across user transactions (rather than clustering transactions, themselves).
However, tranditional clustering algorithms such as distance-based methods generally cannot handle this type of clustering. The Association Rule Hypergraph Partitioning(ARHP) technique is found to be well-suited for this task. In this project, you are required to implement the ARHP algorithm to cluster URL references of a Web server log.
Students: Jingyue Zhang, Meng Ding and Joyce Chen
Reference Student: Jia Li
Visualization
Project 12: Immersive data mining
An initial prototype for visualizing 3-dimentional data cubes in an interactive virtual-reality immersive environment has been implemented using the CAVE at UofA.
The project would be to reimplement this prototype using the SGI performer library and include an 3D interactive torus menu system allowing OLAP operations and other ad-hoc data mining operations.
Number of students: 2
Reference Student: Ayman Ammoura
Project 13: Visual Web Mining
Whereas traditional data mining techniques attempt to analyze data automatically, visual data mining techniques enable the user to steer the data mining process, incorporate domain knowledge, and understand the results. Visual data mining is comprised of data visualization, mining process visualization and mining result visualization.
In this project, you are required to implement the Association Rule Mining process visualization and its result visualization, based on the Apriori algorithm, in which you steer the mining process according to your knowledge. The context of this project is web usage mining using a given web log and the structure of a given website.
Students: Minawer Nulahmat, Lisheng Sun and Zhipeng Cai
Reference Student: Jia Li
Project Proposal
The project proposal is supposed to be maximum 2 pages long. It should include: (1) The name of the participants; (2) a description of the problem; (3) references; (4) a methodology to be followed; and (4) a tentative schedule.
Important Dates
- Project proposal due: Tuesday 15 October. (10%)
- Project Initial Demo: Week of November 18-22. (35%)
- Project report due: Monday December 16. (15%)
- Final Demo: Tuesday December 17 and Thursday December 19. (40%)
Projects will count 39% of the overall grade.
|
[Home]
[Announcements]
[Calendar]
[On-line Materials]
[Activities]
[Grading]
[Glossary]
[U-Chat Tool]
[Web Links]
[Student Resources]
|
